Миш, спасибо за отклик. Сейчас сформулирую, загифую), и отпишу. По ходу обдумывания ещё пара идей хороших нарисовались.
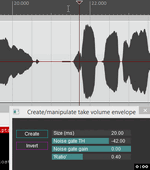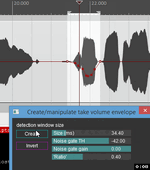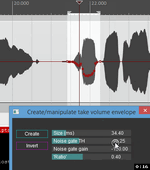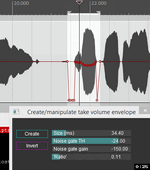
[DOUBLEPOST=1444864214,1444853704][/DOUBLEPOST]Алгоритм работы сейчас приблизительно такой:
https://yadi.sk/i/dVk2o80fjjxiq. Как раз концертный трек, там сильный уровень проникновений, наглядно. Возникающие при редактировании кривой нюансы тоже налицо)
Грубо говоря - выделяю отдельные фразы, глушу всё, что между ними, сами фразы "на глаз" выравниваю по громкости. Таким же макаром чуть тушатся (не до конца) разные вздохи, сибилянты и т.п. - глаз уже натаскан их вычислять. Из нюансов - надо следить за твердыми согласными в начале и конце фрагмента, обычно они негромкие, легко можно их потерять. Микродинамика внутри фраз не очень важна, оставляю это компрессору. А всякую мелочевку дополнительно убивает легкое экспандирование (SEG от Anomaly вне конкуренции).
В общем, если бы была возможность хотя бы по RMS-уровню разбивать итем с аудио на сегменты шум/полезный сигнал одной командой, это спасёт кучу времени. "Танцующая" огибающая с кучей точек (как на
картинке) и не нужна, в принципе. А если научить алгоритм детектировать вздохи (это почти одинаковые "облачка" между фразами) и протяжные сибилянты (та же русская "С" - такая длинная колбаска, например) - ууу... ну, это совсем мечта.
Или же общая "калибровка" - по RMS, а точные позиции - уже пиковые значения, с учётом анализа формы волны на участке. Так много точнее будет. Не знаю, правда, позволяет ли API такие фокусы.
Ручная коррекция в такой работе предпочтительнее любого, хоть суперинтеллектуального гейта - массу нюансов нужно отслеживать на слух и на ходу решать, что оставить, что мютировать, что приглушить. Иначе есть шанс что-то потерять, а на голосе, в отличии от мелизмов музыкальных инструментов, это недопустимо.





")